
STATBEANS® is a collection of JavaBean data-analysis add-ins which implement many commonly used statistical procedures. What are JavaBeans? In this case they data analysis add-ins that are designed to be embedded in user-written applications or placed on web pages. Because of their structure as a component library, they may be easily manipulated in various visual development environments. Users have a choice of accessing STATBEANS® as JavaBeans examples or as ActiveX components using the JavaBeans-ActiveX bridge.
Types of STATBEANS® For Data Analysis
There are four basic types of STATBEANS® as JavaBeans examples:
 DataSource STATBEANS® - These JavaBeans examples maintain a rectangular data table which other STATBEANS® access to retrieve data for analysis. DataSource STATBEANS® are provided for reading data from local text files, for reading data over the Internet or local intranets, for accessing databases via JDBC, and for maintaining data generated by user programs.
DataSource STATBEANS® - These JavaBeans examples maintain a rectangular data table which other STATBEANS® access to retrieve data for analysis. DataSource STATBEANS® are provided for reading data from local text files, for reading data over the Internet or local intranets, for accessing databases via JDBC, and for maintaining data generated by user programs.
 Calculation STATBEANS® - These are non-visible beans which perform statistical calculations. They may be called by user programs to calculate statistics. They are also accessed by the tabular and graphical STATBEANS®.
Calculation STATBEANS® - These are non-visible beans which perform statistical calculations. They may be called by user programs to calculate statistics. They are also accessed by the tabular and graphical STATBEANS®.
 Tabular STATBEANS® - These are JavaBean examples that perform statistical calculations and display them in the form of tables.
Tabular STATBEANS® - These are JavaBean examples that perform statistical calculations and display them in the form of tables.
 Graphical STATBEANS® - The STATBEAN® data-analysis add-ins perform statistical calculations and display them in the form of graphs. Users create applications by first adding what are JavaBeans' datasources along with the STATBEANS® to their project, and then linking the other STATBEANS® to the datasource.
Graphical STATBEANS® - The STATBEAN® data-analysis add-ins perform statistical calculations and display them in the form of graphs. Users create applications by first adding what are JavaBeans' datasources along with the STATBEANS® to their project, and then linking the other STATBEANS® to the datasource.
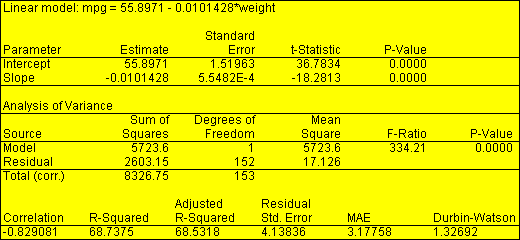
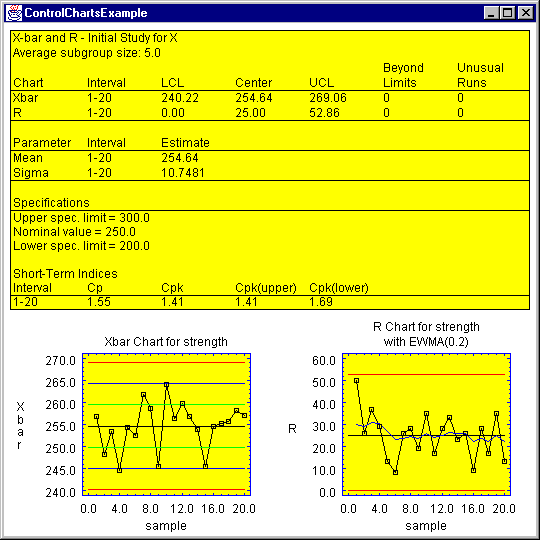
STATBEAN or JavaBeans examples are included throughout this section. In addition, sample java files are distributed with the system which implement each STATBEAN as a simple Java application. The data-analysis add-in sample files have names such as ControlChartsExample.java, which creates the following output:
.gif)
Notes
Some special features and other items of note are:
Trademark and Copyright Notification
STATBEANS® is a trademark of Statpoint Technologies, Inc. All rights reserved. All STATBEANS® code and documentation is copyright 2015 by Statpoint Technologies, Inc., and is not to be redistributed without express written permission.

© 2023 Statgraphics Technologies, Inc.
The Plains, Virginia
CONTACT US
Have you purchased Statgraphics Centurion or Sigma Express and need to download your copy?
CLICK HERE







